Fig. 8.1
Retinotopic (a) and somatotopic (b) receptive fields. (a). Responses of an idealized neuron encoding the locations of visual stimuli in retinotopic coordinates. Responses are characterized for different locations in allocentric (world-based) coordinates (blue and yellow circles) but the same locations in retinotopic coordinates by varying gaze direction in space. The response profiles (receptive fields) are similar in shape for the two gaze positions and are ‘gain-modulated’ by gaze direction, a common feature of neurons in association cortex [12]. (b). Tactile receptive fields of neurons in somatosensory cortical area 3b obtained from monkeys trained in a tactile frequency-discrimination task. The sizes, shapes and locations of receptive fields are shown for both the trained and untrained hand [13]
The reference frames used by association cortical areas are particularly interesting in the context of movement planning. Since these regions are multimodal in nature it is not evident a priori what reference frame(s) should be used to encode spatial information relevant to movement. For example, information about the current position of the arm must be taken into account to form a plan for a reaching movement. This information can be provided by both visual and somatosensory input. Additionally, motor-related association cortices of the brain typically receive both types of information. As a result, it is not immediately clear if arm position should be represented in a visually-based frame in these areas or in a body-centered one. It is also possible that a hybrid set of coordinates is used. Because of such questions, as well as the fact that (1) coordinate representations are thought to be a distinguishing feature of neurons and neuron populations in sensorimotor networks of the brain, and (2) reference frames and coordinate systems are also an integral part of robot planning and control schemes, we focus almost exclusively on this aspect of neural representations in our review.
In the future, the development of systems requiring intimate and extensive physical interactions between robots and humans, such as neural prosthetic and rehabilitation robotic systems, will benefit from knowledge gained by studying how two or more humans perform cooperative tasks. As a result, we will begin by providing a brief overview of what is known about the performance of such ‘joint actions’, as they are called in the neuroscience community, ending with a discussion of joint manipulative actions involving the hand and arm. We will then discuss the relevance of such studies for robot-robot and human-robot interactions. The point here is not to conduct an exhaustive review of human-robot interactions (HRI), as this is beyond the scope of this chapter, but merely to touch upon what is known about collaborative manipulation in HRI. Lastly, we will discuss what is known about the neural representations of hand and arm movements, with a particular emphasis on the coordinate frames for representing spatial variables, such as arm and target position.
8.2 Joint Actions in Humans
Joint actions involve two or more agents coordinating their behavior in space and time to perform a particular task [14]. The ability to engage in such behaviors, while not unique to humans, is most highly elaborated in our species. As pointed out by Tummolini and Castelfranchi [15], only humans have the capability to “create complex tools, structured symbol systems (i.e. language) and social institutions (i.e. government and marriage) as a means to facilitate such coordination and cooperation” [15]. However, most of what we currently know about “joint actions” still comes from studies in social contexts. Observations derived from these studies have led to the conclusion that the successful performance of joint actions in the social domain depends strongly (among other factors) upon the ability to predict the integrated effects of one’s own and others’ actions [16]. This is turn, requires the sharing of internal representations of both the task and mental state of others, a concept known as ‘co-representation’ [14, 17].
Joint actions are also an essential part of many motor-related activities of daily living; examples can be found in sport, as with the passing of a ball between two soccer teammates, art, as during ballroom dancing or the performance of a musical duet, and even rehabilitation, as when a therapist or rehabilitation robot assists a patient during therapeutic exercise. Despite their ubiquitous nature, comparatively little is known about joint actions in the sensorimotor domain. In recent years, research in this area has focused largely on three topics: co-representation (defined above), attentional and perceptual processes, and interpersonal (temporal) coordination [18].
Research on perceptual processes has been directed in part at understanding “motor resonance”, e.g. the idea that observation of someone else’s actions can facilitate the recruitment of corresponding motor representations in observers [19]. Recent findings suggest that even in the absence of contextual information, subjects are able to infer the intentions of others from information derived from movement [20]. For example, Sartori et~al. [21] video-recorded reach-to-grasp movements performed under conditions in which subjects were either intending to cooperate with a partner, compete against an opponent, or perform an action individually. When the video clips were presented to “observer” participants in an intention discrimination task, all three scenarios (cooperative, competitive and individual) were found to be discriminable by the observers [21]. This was true even when visual information about the terminal phases of movement and object contact were occluded. This supports the idea that intent can be inferred even from visual information present in the early stages of a motor action.
Interest in interpersonal coordination is comparatively long standing and has recently expanded from a focus on rhythmic movements [18, 22] to include analyses of non-rhythmic activities [23–25]. For example, Braun and colleagues [24, 25] have recently studied intra- and inter-personal coordination in a virtual rope-pulling game and found evidence for both cooperative and non-cooperative (competitive) behaviors. That is, when two different subjects performed the game together, behavior tended toward a competitive strategy, whereas when individual subjects performed the same task alone but bimanually, behavior tended to be more cooperative. Such results are consistent with a “Nash equilibrium solution”, a concept derived from classical game theory, which predicts that in a two-person game each player will choose a strategy that ensures that neither player has anything to gain by altering their own strategy [26]. Overall, this work suggests that the performance of some joint action tasks can be analyzed successfully within a game theoretic framework.
Research on co-representation addresses how and when two agents are able to form internal representations of tasks and each other’s actions [27]. Co-representation is often studied using a variant of the classical “Simon task,” in which subjects are required to respond to stimuli using responses that are either spatially congruent or incongruent with the stimuli [28]. The “Simon effect” refers to the phenomenon that behavioral reaction times of single subjects are slower for the spatially incongruent responses, as when pushing a button with the right hand in response to a stimulus appearing in left visual space. Interestingly, the same effect can be observed when the Simon task is performed jointly by two subjects. In the basic form of these experiments, each subject is typically responsible for one of the two responses, e.g. one subject for left button presses and one for right button presses. The resulting differences in reaction time that are observed in such tasks is commonly referred to as the “social Simon Effect” [27].
The concept of co-representation and its underlying neural representation is naturally tied to the issue of frames of reference. That is, in forming an internal representation of a joint action, do subjects use the same frame of reference to plan their behavioral responses and if so which reference frame is used? Some investigators have addressed this question using a variant of the social Simon task. For example, in a recent study by Welsh [29], dyads (pairs of subjects) performed the social Simon task standing side-by-side and with their inside or outside hands placed in either a crossed or uncrossed configuration [29]. Welsh found that the social Simon effect was observed in all of these conditions. In other words, the presence of a social Simon effect appeared to be dependent only upon the spatial location of the response keys, and not the relative locations of the subjects in space or the configurations of the responding hands. This has been interpreted as reflecting a preference for ‘external, response-based coordinates’, i.e. visual or allocentric (world-centered) coordinates, in planning joint actions [30], though other work suggests that internal (body-centered) frames can also be used in different contexts [31].
The Welsh study raises the question of whether the apparent dominance of external frames in joint action is related to the use of predominantly visual stimuli. Dolk et~al. [30] recently addressed this issue in sighted and congenitally blind dyads using a variant of the social Simon task that involved responses made to auditory stimuli with the arms either crossed or uncrossed [30] (Fig. 8.2). These investigators found that the social Simon effect was observed in both the arms crossed and uncrossed conditions in sighted individuals, but only in the uncrossed condition for the congenitally blind subjects. This study affirmed the importance of external frames in governing behavioral responses in joint action but also suggested that the type of external reference frame used for planning joint actions is determined by experience. That is, congenitally blind individuals appear to use both response-based and “agent-based” external frames, while sighted individuals tend to use predominantly the former.
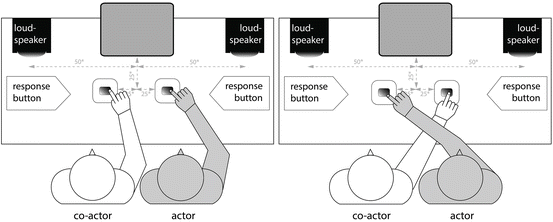
Fig. 8.2
Illustration of an auditory version of the Social Simon task [30]. Subjects performed a reaction time task requiring button presses in response to auditory stimuli. Responses were generated using either a crossed (right) or uncrossed configuration of the actors’ arms
In a recent study with particular relevance to human-robot interaction, electroencephalography signals (EEGs) were recorded from the brain while pairs of subjects performed a joint Simon task [32]. Here subjects made left and right keyboard presses to targets presented either on the right or left side of a computer screen. In one condition subjects performed the task under the belief that they were interacting with a biological agent situated in another room, while in another condition they were told they were performing the task with a computer. In both conditions however, responses of their partner were actually randomly generated by the same computer program. Interestingly, reaction times followed the predictions of the social Simon effect, only in the condition where subjects believed they were acting with a biological agent. In addition, these behavioral differences were reflected in the patterns of EEG activity. These results reinforce the notion that the perceived agency of co-actors influences the representation of planned motor actions in the brain.
8.3 Joint Manipulative Actions of the Hand and Arm
Cooperative, manipulative actions such as pouring liquids into a hand-held glass, turning a large crank or wheel, and transferring of objects between hands (“handovers”) are examples of common joint actions performed between human agents and between humans and humanoid robots [33] (Fig. 8.3). However, little information exists on precisely how such actions are planned controlled and even less information is available regarding how they are represented in the brain. For example, despite the ubiquitous nature of handovers, surprisingly few studies have addressed the planning of these actions in humans and their underlying coordinates. Studies have focused instead on such features as the endpoint kinematics of the hander and receiver [34, 35], the relationship between grip force and load force [36], handover duration [37], and the reaction times of the receiver and spatial position of the handover [38–40].
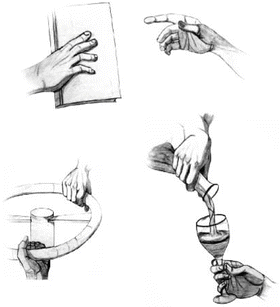
Although handovers have not received a lot of attention to date, these actions are similar in many ways to more well-characterized tasks typically performed by single agents such as reach-to-grasp (RTG). That is, both handovers and RTG involve the following constituent actions: (1) reaching or transport of the hand, (2) orienting of the hand, and (3) hand preshaping (prior to receiving in a handover task or grasping in an RTG task). As a result, object handovers can be thought of as an extension of RTG to the domain of joint actions. These similarities suggest that the relatively large literature on RTG can be used to gain preliminary insight into the behavioral and neural correlates of the joint action of handovers.
A large number of RTG studies in humans have examined the coordinate frames underlying reach planning. As discussed earlier, reach planning requires a comparison between the hand’s current position and the position of the target. In situations where the target and hand can be viewed, both positions can be coded with respect to the current gaze direction. Throughout this review we will use the term “eye-centered” to refer to this coding scheme though the terms “viewer-centered”, “gaze-centered”, or “fixation-centered” have also been used [41–43]. Hand position can also be defined in the hybrid body/arm frame defined by the proprioceptors. It is commonly thought that planning is facilitated by transforming hand and target position into the same set of coordinates (cf. [44]), but precisely which frame is used remains controversial. Evidence for both eye- and/or body-centered coordinates exists in the literature [41, 45–49].
One simple explanation for these disparate results is that the choice of frame is context dependent, with eye-centered coordinates being used in conditions where at least some visual information about both hand and target position is available. For example, when subjects make reaching movements to remembered targets with some visual feedback of the hand, their constant and variable errors suggest that planned reach vectors are computed in a visual or eye-centered frame [42, 45, 49] (Fig. 8.4). This result is consistent with findings that reach plans are dynamically updated in eye coordinates following saccadic eye movements [46], regardless of the sensory modality used to cue these movements [50]. It is also consistent with findings that generalization patterns following local visuomotor perturbations of the fingertip are consistent with eye-centered coordinates [51]. Providing a neurorobotics perspective on the matter, Tuan and colleagues have reported that a planning scheme based on eye-centered coordinates is more robust to sensory biases and delays than schemes based purely on body-centered coordinates, emphasizing the advantage of eye coordinates in certain contexts [52].
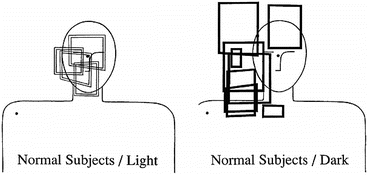
Fig. 8.4
Behavioral evidence supporting context dependent reference frames for reach planning [45]. Each box represents the 95 % confidence limits on the presumed origin of the coordinate system used for planning reaching movements to remembered targets. Data from four subjects in fully-lighted conditions (left) and eight subjects in dark conditions are shown. In the light (i.e. with vision of the hand), the origin is centered around the approximate line of sight, while in the dark the origin is biased for most subjects toward the right shoulder
A somewhat different story emerges when subjects are required to make reaching movements to remembered target locations with little or no visual feedback of the arm. Here, patterns of constant and variable errors support a coordinate system for planning that is at least partially body-centered [42, 45, 49]. Interestingly, similar trends are observed when subjects make movements without delay to visible targets (not remembered ones) but without online visual feedback of the hand [53]. Results such as these suggest that the coordinate frame(s) used to plan human reaching movements are context-dependent, being determined in part by the extent and reliability of relevant visual feedback, particularly regarding the arm [49, 54–59]. Note that this conclusion is also in agreement with a recent study of the social Simon effect, which pointed to context-dependent frames for planning joint actions [31].
The above considerations for representations and frames of reference involved with pointing or reaching are likely to apply to RTG, where proximal limb motion is coupled with hand shaping to grasp an object, i.e., preshaping. Hand preshaping could be considered a process through which object geometry and grasp affordances, expressed in a world-centered frame of reference, drive a sensorimotor transformation leading to the alignment of hand and object frames of reference, culminating in a close match between the opposition axis (i.e., the line connecting the tips of the thumb and index finger [60]) and the graspable axis of an object, or between hand shape and object shape. Rather than addressing this process directly, behavioral studies have mostly focused on the sensory mechanisms underlying the time course of hand shape modulation to object shape. One of the main questions addressed by these studies is the extent to which continuous visual feedback of the hand and/or the object is required to coordinate finger movements leading to a stable grasp at the end of the reach. One possible scenario consists of computing an ‘error’ signal arising from visually-perceived object shape versus hand shape, until the hand can conform to the object at contact. An alternative scenario might involve vision, but not necessarily on a continuous basis. Specifically, object shape visually perceived at reach onset might be sufficient to drive the coordination of finger movement throughout the reach. Behavioral evidence supports the latter scenario, indicating that whole-hand shaping occurs in a similar fashion regardless of whether visual feedback of the object is present or absent during the reach [61]. Interestingly, removing tactile feedback at the end of the reach when reaching to grasp a visible virtual object also leads to a similar hand shaping observed when reaching to grasp a physical object [61]. A follow-up study confirmed these observations by showing that hand preshaping occurs in a similar fashion regardless of whether vision of the hand and object is allowed [62]. Although these observations do not rule out a role for online visual feedback for hand preshaping, they demonstrate that vision of the object prior to initiating a reach is sufficient to drive the spatial and temporal coordination of finger movements in preparation for a grasp.
As with hand preshaping, relatively few RTG studies have focused on the planning and control of hand orientation. Here we define hand orientation as a rotation about the long axis of the forearm, in order to distinguish it from rotations of the opposition axis. The relative lack of attention given to examination of hand orientation is unfortunate, as orienting is a critical component of dexterous manipulation and yet involves fewer mechanical degrees of freedom and muscles than hand preshaping. Although most real world manipulation tasks require precise coordination of both orienting and preshaping, the relative biomechanical simplicity of hand orienting makes it more amenable to study in the laboratory than hand preshaping, particularly with regard to coordinate representations. In addition, damage to certain regions of the cerebral cortex appears to be associated with specific deficits in orienting the hand. For example, patients with optic ataxia resulting from damage to the parietal lobe have also been shown to exhibit difficulty in orienting their hand to match the orientation of a target slot [63]. Similarly, patients with damage to the lateral occipital and parasagittal occipitoparietal cortex have been shown to demonstrate deficits in perceiving the orientation of a visual stimulus during orientation-matching tasks [64]. These studies point to a disruption of the high level sensorimotor transformations required for planning appropriate final wrist orientations following damage to parietal and occipital regions of the brain.
Behavioral studies examining hand orientation have shown that during RTG actions, final hand orientation is influenced by several factors including: (1) the direction of reaching, (2) the initial and final postures of the upper arm before and after the reach, (3) the spatial location and orientation of the target and (4) the optimal grasp axis of the target object [64–78]. In addition, studies involving reaches to objects that unexpectedly change orientation suggest that orienting the hand involves a process whereby a final desired orientation is compared to the initial (or current) hand orientation to compute a desired change in orientation [67, 79]. This suggests that planned changes in orientation are encoded in a relative, rather than absolute, frame of reference at least somewhere in the sensorimotor structures responsible for RTG. As will be demonstrated below, this idea resonates with some recent robotic planning and control schemes and also with recent neurophysiological investigations of eye-hand coordination in the primate brain.
8.4 Joint Manipulative Actions: A Robotics Perspective
As discussed above, handovers serve as an excellent example of joint manipulative actions performed by human agents. Handovers are also a critical action for robots that cooperate closely with humans and, as with other joint actions, successful performance of these handovers depends critically on communication cues exchanged both before and during the action [80]. For example, Cakmak and colleagues [81] examined robot-to-human handovers and demonstrated that both spatial (pose) or temporal aspects of the robot motion can fail to adequately convey the intent of the robot, leading to delayed or failed acceptance of the object by a human collaborator [81]. They proposed addressing these issues by incorporating spatial and temporal motion cues that distinguish handovers from other manipulative actions, and found that temporal cues were particularly useful for enhancing the fluency of handovers. Expression of robot intent has also been explored using body movements, facial expressions and speech [82–84] though not in the context of handovers.
As a result of these and other observations, considerable effort has been put into providing robots and humans with the means to better decode each other’s intentions. For example, Grigore and colleagues [85] showed that the success rate of robot-to-human handovers can be improved by providing the robot with the ability to interpret the human’s current gaze orientation and therefore their locus of attention [85]. Similarly, Huber and colleagues [37] showed that robot-to-human handovers can be facilitated by using robot motion profiles that are consistent with observed human motion profiles. In this study, robot-to-human handovers were examined using both a humanoid and industrial robot [37]. In addition, two different velocity profiles for robot arm motion were used: a trapezoidal velocity profile in joint coordinates and a minimum jerk profile in Cartesian (endpoint) coordinates, the latter being inspired by observations of human reaching movements [86]. Reaction times of the human subjects were found to be shorter for the minimum jerk profiles, regardless of whether the robot was humanoid or industrial, indicating that human preferences for biomimetic motion influence the ability to infer robot intent. Preferences have also been observed with respect to the approach direction of a mobile robot partner and the height and distance of the object being passed [87].
The study of joint manipulative actions between robots and humans has generally ignored the issue of which coordinate frame or frames might best represent these tasks. At least in the laboratory setting, the position and orientation (pose) of the robot and human hands are defined with respect to different absolute frames. For example, for humanoid robots this frame might be fixed to the head or torso of the robot while for humans this frame might be defined with respect to the coordinate system of a motion tracking device. However, effective cooperation on manipulation tasks requires the robot and human to react in real-time to their collaborator’s motion, a feature that is not straightforward to implement using representations involving absolute poses. As a result of these and other difficulties, Adorno and colleagues [33] developed an approach to representing cooperative manipulative tasks by means of the relative configuration between the human’s and the robot’s hands [33]. This approach has the advantage of allowing a large set of tasks, including handovers, to be represented in a similar fashion, and in a manner that is invariant with respect to the physical location of the robot and human/motion tracker in space. Perhaps most importantly, this approach is noteworthy because it resonates with psychophysical studies of the control of human hand orientation during RTG tasks and, as discussed below, with neurophysiological studies of eye-hand coordination tasks.
8.5 Neural Representations of Joint Actions
While significant progress has been made in understanding joint motor actions from a behavioral perspective, almost nothing is known about their corresponding neural correlates [88]. Recent modeling work has emphasized the potential role of the putative mirror neuron system (MNS) in mental state inference, a key component of joint action [89]. The MNS is a group of frontal (ventral premotor) and parietal regions (mainly the anterior intraparietal area) that are believed to play a role in motor learning by observation as well as other high-level cognitive, sensory, and motor functions essential for joint action [19, 90, 91]. Inferring mental states, i.e. knowledge of the required task and goal, during joint actions is highly dependent upon communication cues exchanged between interacting agents. These cues can be provided by visual feedback, in the case where one actor simply observes the other, or by both visual and haptic feedback, in the case where tasks involve physical interaction. Oztop et~al. [89] proposed a computational model of mental state inference in the context of pure visual observation. In this model, inference is facilitated by defining task goals and objectives in visual coordinates, which is in accordance with both recent human [47, 92–95] and animal studies [96, 97]. In this scenario, actions such as reaching are defined simply as difference vectors in visual coordinates. This has the advantage of allowing the actions of both the actor and observer to be treated in a nearly equivalent manner by the observer’s motor planning apparatus, thereby simplifying the inference process.
While this model is elegant in its simplicity, it is currently unclear how well the model can be generalized to conditions of physical interaction involving both visual and haptic feedback, which are not always congruent or equally reliable [98]. The model of Oztop and colleagues could, in principle, be extended to this context if a mechanism existed to transform haptic information from the hybrid arm/body-centered coordinates of proprioceptive and tactile feedback to the natural coordinates of visual processing (eye coordinates), an idea that is not without precedence [57, 99–103]. However, it is also possible that integration is achieved using the principles of optimal cue integration, which does not require transformation of feedback into a common reference frame and would directly take into account the relative reliabilities of the sensory cues [104, 105].
In agreement with the work of Oztop et~al. [89], recent fMRI studies in humans point to the MNS as a potential neural substrate for many joint actions [106, 107]. An important element to models such as the one proposed by Oztop et~al. is the idea of simulation. To predict the actions of an observed agent, one could use the same neural systems that underlie movement planning to simulate the movements of others and thereby deduce the intentions of an observed act. Consistent with this idea, activation has been observed in the cortical areas associated with the MNS both when subjects balance a bar and when they observe a bar being balanced [108]. When extended to joint action, i.e. the subjects cooperating with another agent in balancing the bar, activation in the same cortical areas was further facilitated. This would be consistent with the MNS having a special involvement in joint action.
While studies such as these suggest a significant contribution of the MNS to joint action, these studies may be limited by focusing too carefully on shared corresponding actions. Kokal et~al. [106] pointed out that the examination of joint action should be expanded to include the coding of complementary, as well as corresponding, actions. For example, if two people are engaging in a hand-off, one agent is presenting and releasing an object, while the other agent is receiving and grasping. Thus, a neural system which participates in joint action needs to be more flexible than simply coding the same action irrespective of the actor. Kokal and colleagues constructed a set of joint action tasks in which the two agents either performed the same motion, or opposite and complementary movements to achieve the joint goal. Under these conditions conjugate and complementary tasks facilitated activity not only in the fronto-parietal areas conventionally associated with the MNS, but also in additional cortical areas in the occipital and parietal lobes. Thus, while the mirror neuron system is likely an important element in the neural architectures which subserve joint action, it may not be the only element recruited during joint action performance.
Although human imaging studies have provided crucial information regarding the anatomical loci of joint action representations, methods such as fMRI are unable to shed light on precisely how these actions are represented at the level of single neurons or small ensembles. However, single and multi-unit studies in non-human primates are ideally suited for probing such representations. Neurons in the MNS have some of the properties one would expect of neurons that participate in a joint action system. In particular, neurons in both the posterior parietal cortex (PPC) and ventral premotor cortex (PMv) have been shown to exhibit similar activity for both motor execution and observed action. In each of these cortical regions, neurons have been observed which encode elements of grasp, including the configuration and orientation of objects that are about to be grasped and the hand configuration that is being used to carry out those grasps [109, 110]. That these neurons have similar coding for actual grasps and observed grasps is evidence for their participation in joint actions. Especially notable in the context of joint action is the observation that many neurons in PMv appear to encode implied actions [111]. When vision of the final phase of an observed grasp task is blocked, some neurons in PMv still code the unseen grasp, suggesting that they were in fact being used to simulate and predict the movements of other agents.
An important principle in the neural representation of task space is effector independence: neurons in networks coding for task performance should show aspects of coding that do not depend on the effector performing the task. Simultaneous multi-unit chronic recordings in PPC and PMv during feeding tasks suggest there are a number of similarities in the way that observed and executed tasks are coded, but there is also one important difference [112]. The coding of observed action in PMv appears to have an element of effector-dependence, whereas the coding of observed action in posterior parietal cortex has a measure of effector independence. This kind of task-focused encoding is closer to reflecting the quality of flexibility that Kokal et~al. [106] suggested should be an additional hallmark of neuronal systems that support joint actions. To date, however, there have not been reports of recordings undertaken specifically with the goal of gaining insight into the neural coding of joint actions.
Other more dorsally-situated parts of the premotor and parietal cortices, including the dorsal premotor cortex (PMd), parietal area 5, the medial intraparietal area and parietal area V6A (Fig. 8.5), have been shown to be involved in integrating visual, somatosensory and motor signals in support of goal-directed actions such as reaching and grasping and in the forming of motor “intentions”, i.e. high level plans for movement [96, 114–118]. These regions could therefore also play a role in the planning and/or execution of joint actions. Activity in these areas is similar in many respects. Being association areas of the cortex, neurons in the parietal and premotor regions often exhibit both sensory- and motor-related responses. In addition, many neurons exhibit responses that reflect higher-order cognitive processes such as movement planning. Movement planning is typically examined using some form of memory-guided delayed response task [119]. Such tasks involve training animals to withhold their response to a presented cue for periods lasting as long as several seconds, then cueing them to make the appropriate response. The benefit of such tasks for understanding sensorimotor processing is the following: by incorporating a delay period, activity related to planning a motor response can be temporally dissociated from both simple sensory responses to the presented instructional cue and the processes involved in movement execution, including sensory feedback.
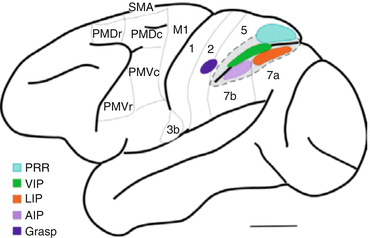
Fig. 8.5
Lateral view of the macaque monkey brain, highlighting many of the areas discussed in this review [113]. PRR parietal reach region, VIP ventral intraparietal area, LIP lateral intraparietal area, AIP anterior intraparietal area, Grasp area 2 grasp –related area, M1 motor cortex, SMA supplementary motor area, PMDr dorsal premotor cortex, rostral subdivision, PMDc dorsal premotor cortex, caudal subdivision, PMVr ventral premotor cortex, rostral subdivision, PMVc ventral premotor cortex, caudal subdivision, PMVr (also referred to as F5) represents the frontal node of the mirror neuron system in monkeys, AIP and area PFG represent the parietal node [19], the latter corresponding roughly to what is labeled 7b in this figure
Delayed response tasks have provided evidence for movement planning processes in a number of arm and hand movement related areas of the frontal cortex. Moreover, evidence for the planning of both kinematic and dynamic (kinetic) variables has been uncovered. For example, neurons in areas such as the motor cortex (M1), dorsal premotor cortex (PMd) and supplementary motor area (SMA), have been shown to represent high-level parameters of upcoming movements, including movement direction, amplitude and speed, during the delay periods of delayed response tasks [120–125]. These same areas appear to represent the impending dynamics associated with arm movements, consistent with a role in the planning of kinetic variables such as endpoint forces or torques [8–10, 126]. Regarding the encoding of kinematics, a particularly noteworthy study is one by Hocherman and Wise [6]. These investigators trained animals to move between identical starting and goal locations but using different (curved) trajectories and found that the activity of some neurons differentiated among such trajectories [6]. In this way, these investigators were the first to show that the planning of detailed movement trajectories can be represented in the discharge of cortical neurons.
In the parietal cortex, the origin of activity occurring during the memory period of delayed response tasks has proven to be much more controversial, with some interpreting this activity as reflecting previous sensory events or attention-related phenomena rather than planning [127]. However, several studies have now provided strong evidence that this activity is viewed in part as reflecting plans for impending movements [118, 128–132]. Regarding arm movements specifically, activity in medial intraparietal area (MIP) and area 5 appears to be consistent with transforming information about target positions and the current position of the hand into a desired movement vector [57, 97, 133]. Recent TMS, imaging, and clinical studies in humans are largely consistent with this view [47, 93–95, 134]. The specific coordinate frames thought to underlie these computations are discussed in detail below.
What about more detailed aspects of movement plans? Torres et~al. [7] recently reported the results of a study where animals planned and executed a block of direct (point-to-point) reaches between two locations on a curved, vertical surface, then attempted to move between those same locations in the presence of an obstacle. Moving in the presence of the obstacle required the animals to use very different movement trajectories to complete the task and, in this way, memory activity for the same starting position and target position but different movement paths could be compared. This design was similar to that of Hocherman and Wise [6] except that in that study, the different trajectories were explicitly instructed using a visually-presented path while in the study by Torres et~al. [7], no such instruction was provided. Nevertheless, animals gradually adopted stereotyped trajectories that allowed them to successfully avoid the obstacles. Moreover, memory activity in MIP very clearly distinguished between trajectories planned in the presence and absence of the obstacle, with the activity of some cells being enhanced when the obstacle was present and others being suppressed. The findings support the idea that MIP plays an important role in movement planning, and moreover, that it is involved not only in specifying high level movement parameters such as movement direction and amplitude, but in mapping these plans into corresponding movement trajectories.
8.6 Coordinate Representations for Reaching: Parietal Cortex
The coordinate representations for reaching have been studied most extensively in the parietal lobe, particularly its more posterior subdivision, the PPC. This makes sense as the PPC is an association area of the brain that receives information from multiple sensory modalities and, in addition, projects to frontal lobe areas more directly involved in control of the arm. The PPC is also known to play a role in high-level aspects of movement planning. In addition to previously described evidence, damage to this area results in a number of sensorimotor deficits that are consistent with the idea that the PPC plays a role in transforming sensory information into motor output. Among these disorders is optic ataxia, characterized by misreaching to visual targets. Importantly, patients with this disorder do not exhibit an inability to move their arms or to perceive the locations of visual stimuli but demonstrate a specific deficit in linking motor and sensory representations together to guide movements [63].
In non-human primates, the coordinate frames underlying arm movement planning and execution have been studied by training animals to reach under conditions where arm and/or target positions are held constant in one frame of reference (e.g. with respect to the body) while simultaneously being varied in other frames (e.g. eye or head-centered coordinates). The underlying assumption of this design is that neurons encoding spatial variables in one frame of reference should be unaffected by changing their location in another frame of reference. For example, the activity of a neuron encoding information in body-fixed coordinates should remain invariant if the position of the hand and target remain fixed with respect to the body (even if body position is changed in space) and should, therefore, be unaffected by manipulating the direction of gaze, which alters the position of the hand and target with respect to the eye.
Such experimental manipulations were first used to explore the coordinate frames of arm movement related activity in the parietal reach region (PRR), a part of the PPC located within the bank of the intraparietal sulcus which largely overlaps the previously identified MIP and V6A. In initial experiments, reach targets were varied in arm and eye coordinates on individual trials by varying the starting position of the arm and point of visual fixation [96] (Fig. 8.6). Surprisingly, the activity of many neurons in this movement-related area was invariant when target locations were identical in an eye-fixed reference frame (i.e. with respect to where the animal was fixating), rather than an arm or body-fixed frame. It should be noted however that the activity of a subset of neurons in this area was also modulated by changing the position of the arm. Importantly, changing arm position did not alter the coordinate frames used to encode target position. That is, such neurons were still ‘tuned’ to the position of the target in eye-coordinates; changing the position of the arm simply scaled the responses of the neuron up or down (cf. Fig. 8.1a). Interestingly, the extent of this scaling did not depend on the position of the arm with respect to the body or in space, but depended instead on the location of the hand with respect to gaze. Thus, many PRR neurons appear to encode information about the location of both the hand and target in eye-fixed coordinates and could, therefore, be considered to be encoding (at least implicitly) the required movement vector in an eye-centered reference frame as well [57, 97, 135].
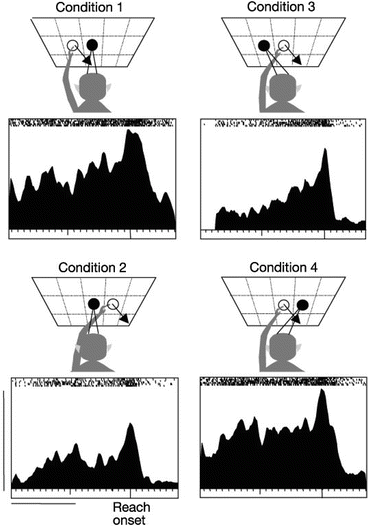
Fig. 8.6
Mixed or hybrid reference frames for reaching in the PPC [97]. Responses of a single neuron in an experiment where initial hand location and/or gaze direction were varied on a trial-by-trial basis. Responses were most similar under conditions where hand locations and target locations were identical with respect to gaze (i.e. conditions 1 and 4 and also conditions 2 and 3), despite the fact that these corresponded to different locations with respect to the body/space. Such responses could be interpreted as reflecting a hybrid representation encoding target location in both eye- and hand-centered coordinates
The coordinate frames for reaching have subsequently been investigated in other areas of the PPC as well. In one such study, responses were examined in the caudal part of area 5, immediately adjacent to the intraparietal sulcus [97]. Using the identical experimental paradigm employed by Batista et~al. [96], it was found that most neurons did not encode reach-related variables in any single reference frame; rather, the responses of these neurons were more consistent with a mixed or hybrid representation reflecting both eye- and arm-centered coordinates (Fig. 8.6). More specifically, the tuning of these neurons varied when either arm position or eye position was varied but, similar to PRR, was most consistent when the initial hand position and target position were identical with respect to gaze direction. This conclusion was confirmed in a subsequent experiment employing a wider range of target locations and hand positions arranged along the horizontal dimension. Lastly, additional analyses showed that this representation was workspace invariant and did not appear to depend on vision of the hand prior to reaching [133].
One limitation of the experimental paradigms employed by Batista et~al. [96] and Buneo et~al. [97] is that target position, arm position and eye position were not independently varied. More recent studies of neural reference frames in the PPC and dorsal premotor cortex have addressed these limitations by independently varying the position of the eyes, arm, and target along a horizontal axis. For example, Bremner and Andersen [136] recently examined the reference frames for reach-related activity in the dorsal subdivision of area 5, more rostral (anterior) to the part of area 5 examined by Buneo et~al. [97]. They found that neurons in this area do not appear to use eye-fixed coordinates at all; rather they appear to largely encode the difference between the current target and hand locations (the movement vector) in a gaze-independent manner [136].
Related posts:
 Robotic Systems for Gait Rehabilitation
Robotic Systems for Gait Rehabilitation
 Home-Based Rehabilitation: Enabling Frequent and Effective Training
Home-Based Rehabilitation: Enabling Frequent and Effective Training
 A Human Augmentation Approach to Gait Restoration
A Human Augmentation Approach to Gait Restoration
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


