CHAPTER 2 PRINCIPLES OF NEUROPSYCHOMETRIC ASSESSMENT
It might legitimately be asked why this chapter was written by both a neurologist and a neuropsychologist. The answer, in part, is that a neurologist who has worked closely with neuropsychologists is perhaps in the best position to interpret the discipline to his or her colleagues; neuropsychology is often a “black box” to neurologists, to a greater extent than neuropsychologists themselves may realize. This can lead to uncritical acceptance of neuropsychologists’ conclusions without the productive interaction that characterizes, for example, neuroradiological review sessions. At the other extreme, the real added value of expert neuropsychological assessment may be discounted by those unconvinced of its validity. In any event, the value of neuropsychological assessment is considerably increased when the neurologist requesting it understands its strengths, limitations and pitfalls, and the sort of data on which its conclusions are based.
COGNITIVE DOMAINS AND NEUROPSYCHOLOGICAL TESTS
Cognitive Domains
Cognitive domains are constructs (intellectual conceptualizations to explain observed phenomena, such as gravity) invoked to provide a coherent framework for analysis and testing of cognitive functions. The various cognitive processes in each domain are more or less related and are more or less independent of processes in other domains. Although these domains do not have strict, entirely separable neuroanatomical substrates, they do each depend on particular (but potentially overlapping) neural networks.1 In view of the way in which cognitive domains are delineated, it is not surprising that there is some variation in their stated number and properties, but commonly recognized ones with their potential neural substrates are listed in Table 2-1.
TABLE 2-1 Commonly Assessed Cognitive Domains and Their Potential Neural Substrate
| Domain | Main Neural Substrate |
|---|---|
| Attention | Ascending reticular activating system, superior colliculus, thalamus, parietal lobe, anterior cingulate cortex, and the frontal lobe |
| Language | Classical speech zones, typically in the left dominant hemisphere, including Wernicke’s and Broca’s areas, and the angular gyrus |
| Memory | Hippocampal-entorhinal cortex complex |
| Frontal regions | |
| Left parietal cortex | |
| Object recognition (visual) | Ventral visual system: occipital regions to anterior pole of temporal lobe |
| Spatial processing | Posterior parietal cortex, frontal eye fields, dorsal visual system |
| Inferotemporal/midtemporal and polar temporal cortex | |
| Executive functioning | Frontal-subcortical circuits, including dorsolateral prefrontal, orbital frontal, and anterior cingulate circuits |
Neuropsychological Assessment of Individual Cognitive Domains
In practice, although many neuropsychological tests assess predominantly one domain, very few in routine clinical use are pure tests of a single domain, and almost all can be performed poorly for several reasons. For example, inability to copy the Rey Complex Figure might result from impairments of volition, comprehension, planning, or praxis, as well as from some form of the most obvious cause of visual impairment. Assignment of particular tests to particular domains is therefore to some extent arbitrary; many tests are capable of being assigned to more than one domain. The interested reader is referred to Lezak and colleagues (2004) and Spreen and Strauss (1998) for details of individual tests. Multidimensional tests, such as the Mini-Mental State Examination (MMSE), may be subjected to factor analysis. This type of analysis identifies groupings of test items that correlate with each other and may well assess aspects of the same domain. In this way, the range of domains assessed by such a test may be identified.
Prerequisites for Meaningful Testing
Adequate testing within some domains requires that some others are sufficiently intact. For example, a patient whose sustained, focused attention (concentration) is severely compromised by a delirium is unable to register a word list adequately. Consequently, delayed recall is impaired, even in the absence of a true amnesia or its usual structural correlates. A patient with sufficiently impaired comprehension may perform poorly on the Wisconsin Card Sorting Test because the instructions were not understood, rather than because hypothesis generation was compromised. These considerations give rise to the concept of a pyramid of cognitive domains, with valid testing at each level dependent on the adequacy of lower level performance2 (Fig. 2-1).
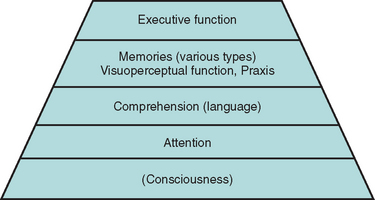
In addition to intact attention and comprehension, patient performance may be compromised by poor motivation—for example, as a result of depression or in the setting of potential secondary gain—or by anxiety. Neurological impairments (e.g., poor vision, ataxia), psychiatric comorbid conditions, preexisting cognitive impairments (e.g., mental retardation), specific learning difficulties or lack of education (e.g., resulting in illiteracy), and lack of mastery of the testing language can all interfere with valid testing and must be carefully considered by the neuropsychologist in interpreting test results.3
BASIC PRINCIPLES OF PSYCHOMETRICS
Test Validity
All readers presumably score 75% on this test, which is therefore absolutely reliable but quite invalid as a test of semantic knowledge.
Concurrent validity, another form of criterion validity often used instead, involves comparing test results with a nontest parameter of relevance, such as sustained, directed attention in children with their class disciplinary records. Ecological validity, a related concept, reflects the predictive value of the test for performance in real-world situations. For example, neuropsychological tests of visual attention and executive function, but not of other domains, have been found to have reasonable ecological validity for predicting driving safety, in comparison with the “gold standard” of on-road testing.4
Content validity concerns checking the test items against the boundaries and content of the domain (or portion of the domain) to be assessed. Face validity exists when, to a layperson (such as the subject undergoing testing), a test seems to measure what it is purported to measure. Thus, a driving simulator has good face validity as a test of on-road safety, whereas an overlapping figures test of figure/ground discrimination may not, even though it may actually be relevant to perceptual tasks during driving. More detailed discussions of reliability and validity were given by Mitrushina and associates (2005), Halligan and colleagues (2003), or Murphy and Davidshofer (2004).
Symptom Validity Testing
Symptom validity testing is rather different and is used as a method to reveal nonorganic deficits (e.g., malingering). It relies on the fact that patients with no residual ability in a domain, who are forced to respond to items randomly or by guessing, can nevertheless sometimes be correct by chance. Performance at statistically significantly worse than chance levels can be explained only by some retention of ability in that domain, with that ability being used (consciously or unconsciously) to produce incorrect answers. This forced-choice/statistical analysis concept should already be familiar to neurologists, as it underlies much of psychophysically correct sensory testing. (A fine example is the University of Pennsylvania Smell Identification Test [UPSIT] for evaluation of olfaction.5)
Other methods for detecting nonorganic deficits also exist; they depend on recognition of deviation from the usual patterns of cognitive impairment (e.g., recognition memory’s being worse than spontaneous recall) or discrepancy between scores on explicit tests of a domain and behavior or other tests implicitly dependent on that domain (e.g., dysfluency appearing only when “language” is tested). This subject is covered in more detail elsewhere.6
Ceiling and Floor Effects
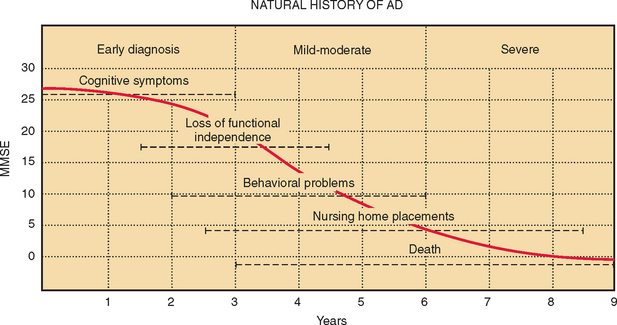
Two further difficulties may limit the use of neuropsychological measures: lack of discrimination across the range of abilities expected and practice effects on repeated testing. An ideal test would reveal a linear decline in ability in the tested domain, from the supremely gifted to the profoundly impaired. In practice, this is rarely, if ever, achieved. Some tests discriminate well between patients with different severities of obvious impairment but are problematic in attempts to detect subtle disorders and fail to stratify the normal population appropriately. This is known as a ceiling effect. On the other hand, some tests sensitive to subtle declines and capable of stratifying the normal population, are too difficult for patients with more profound deficits. Real differences in their residual abilities may be missed. This is a floor effect. Some tests have both ceiling and floor effects, leading to a sigmoid curve of scores versus ability. If patients with Alzheimer’s disease are assumed to decline at a constant rate, then on average, over time, the MMSE shows both ceiling and floor effects (Fig. 2-2).
< div class='tao-gold-member'>





Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


