(1)
where J ij denotes a connection from the j-th to i-th neuron,
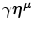 is an input pattern
is an input pattern 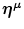 of input strength γ, and μ is index of learned mappings. For a learned input pattern
of input strength γ, and μ is index of learned mappings. For a learned input pattern 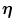 , we set a pattern
, we set a pattern 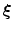 as a target (each pattern is a binary random pattern). The synaptic connection J ij evolves according to
as a target (each pattern is a binary random pattern). The synaptic connection J ij evolves according to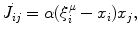
(2)
![$$[\boldsymbol{\eta ^{\mu }}\boldsymbol{\eta ^{\mu +1}}]/N = [\boldsymbol{\xi ^{\mu }}\boldsymbol{\xi ^{\mu +1}}]/N = C$$](/wp-content/uploads/2016/09/A315578_1_En_73_Chapter_IEq5.gif) . Here,
. Here, ![$$[\cdots \,]$$](/wp-content/uploads/2016/09/A315578_1_En_73_Chapter_IEq6.gif) means the average over random patterns of input and target. Every mapping is learned in reverse numerical order from
means the average over random patterns of input and target. Every mapping is learned in reverse numerical order from 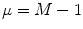 to μ = 0. Further, a system learns the set iteratively in the same order.
to μ = 0. Further, a system learns the set iteratively in the same order.3 Results
Through the learning process, the memories of mappings are embedded in the system. First, in order to evaluate the response of the system to the learned input, we measured the average overlap ![$$[< \overline{\boldsymbol{x\xi ^{\mu }}}/N >]$$
” src=”/wp-content/uploads/2016/09/A315578_1_En_73_Chapter_IEq8.gif”></SPAN> upon <SPAN class=EmphasisTypeItalic>η</SPAN> <SUP><SPAN class=EmphasisTypeItalic>μ</SPAN> </SUP>as a function of <SPAN class=EmphasisTypeItalic>μ</SPAN> for <SPAN class=EmphasisTypeItalic>C</SPAN> = 0. 9 and 0. 1, shown in Fig. <SPAN class=InternalRef><A href=]() 1a, where
1a, where  ,
, 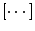 mean the average over time, initial states of one network, and networks, respectively. Note that the response is defined here as an activity in the presence of an input, not as an evoked activity by a transient input used only for the initial condition as in the Hopfield model. For C = 0. 9 and 0. 1, the average overlap with the latest learned target (μ = 0) takes nearly unity and this target can be recalled perfectly. The average overlap with the earlier learned target decreases rapidly and then, saturates at around 0.8 for C = 0. 9, whereas the overlap keeps nearly unity for C = 0. 1. Interestingly, memory performance of the system that learns a set with lower correlation is greater than that with a higher correlation.
mean the average over time, initial states of one network, and networks, respectively. Note that the response is defined here as an activity in the presence of an input, not as an evoked activity by a transient input used only for the initial condition as in the Hopfield model. For C = 0. 9 and 0. 1, the average overlap with the latest learned target (μ = 0) takes nearly unity and this target can be recalled perfectly. The average overlap with the earlier learned target decreases rapidly and then, saturates at around 0.8 for C = 0. 9, whereas the overlap keeps nearly unity for C = 0. 1. Interestingly, memory performance of the system that learns a set with lower correlation is greater than that with a higher correlation.
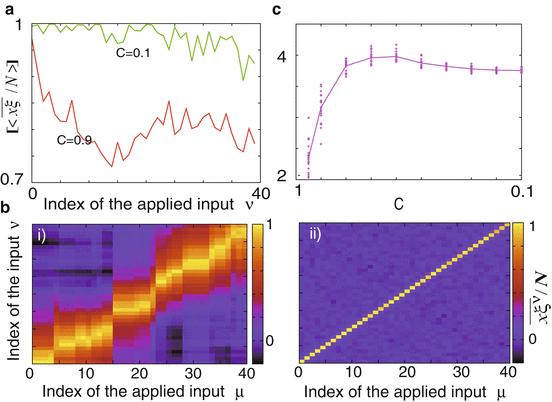
, mean the average over time, initial states of one network, and networks, respectively. Note that the response is defined here as an activity in the presence of an input, not as an evoked activity by a transient input used only for the initial condition as in the Hopfield model. For C = 0. 9 and 0. 1, the average overlap with the latest learned target (μ = 0) takes nearly unity and this target can be recalled perfectly. The average overlap with the earlier learned target decreases rapidly and then, saturates at around 0.8 for C = 0. 9, whereas the overlap keeps nearly unity for C = 0. 1. Interestingly, memory performance of the system that learns a set with lower correlation is greater than that with a higher correlation.Fig. 1
 Integrated Neuropsychiatric Assessment System: A Generic Platform for Cognitive Neurodynamics Research
Integrated Neuropsychiatric Assessment System: A Generic Platform for Cognitive Neurodynamics Research
 Dynamic Temporal-Topological Structure of Brain Network Within ADHD
Dynamic Temporal-Topological Structure of Brain Network Within ADHD
 Activity Patterns in Cortical Dynamics and the Illusion of Localized Representations
Activity Patterns in Cortical Dynamics and the Illusion of Localized Representations
 on the Neural Energy Coding
on the Neural Energy Coding
 Cortical Singularities During the Cognitive Cycle Using Random Graph Theory
Cortical Singularities During the Cognitive Cycle Using Random Graph Theory
 Electrodiffusive Formalism for Ion Concentration Dynamics in Excitable Cells and the Extracellular Space Surrounding Them
Electrodiffusive Formalism for Ion Concentration Dynamics in Excitable Cells and the Extracellular Space Surrounding Them




(a) The average overlap ![$$[< \overline{\boldsymbol{x\xi ^{\nu }}}/N >]$$
” src=”/wp-content/uploads/2016/09/A315578_1_En_73_Chapter_IEq12.gif”></SPAN> in the presence of the input <SPAN class=EmphasisTypeItalic>ν</SPAN> is plotted for <SPAN class=EmphasisTypeItalic>C</SPAN> = 0. 1 and 0. 9, where larger <SPAN class=EmphasisTypeItalic>ν</SPAN> represents earlier learned input. (<SPAN class=EmphasisTypeBold>b</SPAN>) The average overlap <SPAN id=IEq13 class=InlineEquation><IMG alt=]() $$
” src=”/wp-content/uploads/2016/09/A315578_1_En_73_Chapter_IEq13.gif”> with the target μ in the presence of the input ν is shown for (i) C = 0. 9 and (ii) C = 0. 1. (c) The basin entropy Σ v i log v i is plotted as a function of C
$$
” src=”/wp-content/uploads/2016/09/A315578_1_En_73_Chapter_IEq13.gif”> with the target μ in the presence of the input ν is shown for (i) C = 0. 9 and (ii) C = 0. 1. (c) The basin entropy Σ v i log v i is plotted as a function of C
Related posts:
Integrated Neuropsychiatric Assessment System: A Generic Platform for Cognitive Neurodynamics Research
Dynamic Temporal-Topological Structure of Brain Network Within ADHD
Activity Patterns in Cortical Dynamics and the Illusion of Localized Representations
on the Neural Energy Coding
Stay updated, free articles. Join our Telegram channel
Full access? Get Clinical Tree
