9 Basic Statistics for Electrodiagnostic Studies
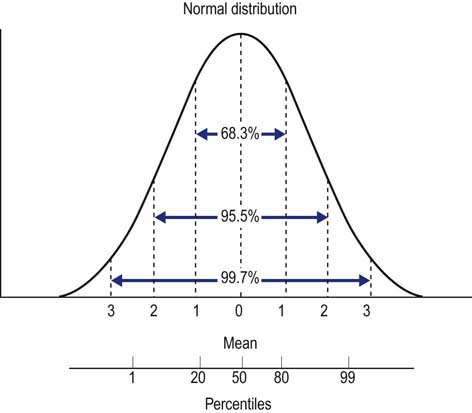
No two normal individuals have precisely the same findings on any biologic measurement, regardless of whether it is a serum sodium level, a hematocrit level, or a distal median motor latency. Most populations can be modeled as a normal distribution, wherein there is a variation of values above and below the mean. This normal distribution results in the commonly described bell-shaped curve (Figure 9–1). The center of the bell-shaped curve is the mean or average value of a test. It is defined as follows:
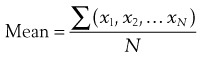
where x = an individual test result, and N = total number of individuals tested.
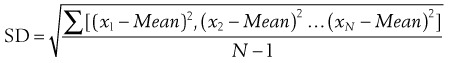
The reasons that the SD is such a useful measure of the scatter of the population in a normal distribution are as follows (Figure 9–1):
• The range covered between 1 SD above and below the mean is about 68% of the observations.
• The range covered between 2 SD above and below the mean is about 95% of the observations.
• The range covered between 3 SD above and below the mean is about 99.7% of the observations.
• All observations up to 2 SD beyond the mean include approximately 97.5% of the population.
• All observations up to 2.5 SD beyond the mean include approximately 99.4% of the population.
The specificity of a test is the percentage of all patients without the condition (i.e., normals) who have a negative test. Thus, when a test is applied to a population of patients who are normal, the test will correctly identify all patients as normal who do not exceed the cutoff value (true negative); however, it will misidentify a small number of normal patients as abnormal (false positive) (Figure 9–2, left). It is important to remember that every positive test is not necessarily a true positive; there will always be a small percentage of patients (approximately 1–2%) who will be misidentified.
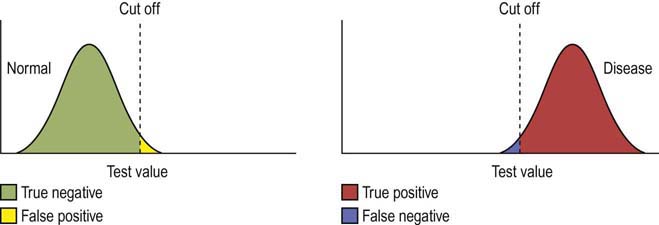
The sensitivity of a test is the percentage of all patients with the condition who have a positive test. When a test is applied to a disease population, the test will correctly identify all abnormal patients who exceed the cutoff value (true positive); however, it will misidentify a small number of abnormal patients as normal (false negative) (Figure 9–2, right). Thus, it is equally important to remember that every negative test is not necessarily a true negative; there will always be a small percentage of abnormal patients (approximately 1–2%) who will be misidentified as normal. Thus, the specificity and sensitivity can be calculated as follows:
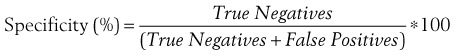

In an ideal setting, there would be no overlap between a normal and a disease population. Then, a cutoff value could be placed between the two populations, and such a test would have 100% sensitivity and 100% specificity (Figure 9–3, left). However, in the real world, there is always some overlap between a normal and disease population (Figure 9–3, right). If a test has very high sensitivity and specificity, it will correctly identify nearly all normals and abnormals; however, there will remain a small number of normal patients misidentified as abnormal (false positive) and a small number of abnormal patients misidentified as normal (false negative).
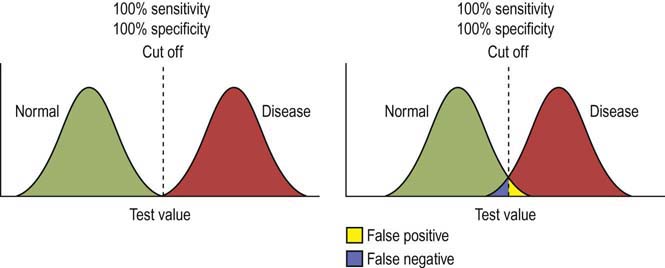
Often there is a compromise between sensitivity and specificity when setting a cutoff value. Take the example of a normal and a disease population where there is significant overlap between the populations for the value of a test. If the cutoff value is set low, the test will have high sensitivity but very low specificity (Figure 9–4). In this case, the test will correctly diagnose nearly all the abnormals correctly (true positive) and will only misidentify a few as normal (false negative) (Figure 9–4, left). However, the tradeoff for this high sensitivity will be low specificity. In this case, a high number of normal patients will be classified as abnormal (false positive) (Figure 9–4, right).
Related posts:






Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


