Chapter 23 Participants Clinical Trials are Authoritative: Shobhan Vachhrajani, Abhaya V. Kulkarni, and James T. Rutka The Flaws of Randomized Clinical Trials: Benedicto Colli Moderators: The Randomized Clinical Trial: A. John Popp, Urvashi Upadhyay, and Robert E. Harbaugh The past two decades have seen a paradigm shift in the practice of medicine away from anecdotal approaches toward evidence-based medicine (EBM). A landmark article by the EBM Working Group1 published in 1992 laid the groundwork for dissemination of this concept. In the group’s opinion, EBM “de-emphasizes intuition, unsystematic clinical experience, and pathophysiologic rationale as sufficient grounds for clinical decision making and stresses the examination of evidence from clinical research.” The concept of EBM has since been refined, and its founders suggest that its scientific basis rests on three key principles. First, clinical decisions should be based on systematic summaries of the highest quality evidence available. Second, wise use of the literature must incorporate a hierarchy of evidence. Third, clinical decisions cannot be entirely based on evidence: they also require the trading of risks and benefits, inconvenience, and costs with consideration for patient values and preferences.2 Critics of EBM argue that currently used evidence grading systems too often discount the value of studies that they deem inferior.3 With a growing emphasis on the development of evidence-based clinical practice guidelines, which rely on systematic grading and interpretation of evidence, this debate only becomes more important. Neurosurgery as a specialty has been slow to adopt the tenets of EBM.4 In many cases, clinical decisions remain dogmatic, largely due to the emphasis placed on personal experience and a lack of education about EBM methodologies.5 Nevertheless, many recent major advances in neurosurgery have resulted from randomized controlled trials (RCTs), which represent the ultimate expression of high-quality evidence. Further advancement of neurosurgical practice will require clinicians to embrace the scientific basis of EBM and to understand the relative hierarchy of medical evidence. This chapter discusses key methodological issues in the design of clinical trials, exposes some of their limitations, and describes the recent impact of RCTs on neurosurgical practice. The hierarchy of medical evidence is based on the progressive minimization of bias. Bias is any process or factor that serves to systematically deviate study results away from the truth. Historically, grading of medical evidence has been based solely on study design. The Canadian Task Force on the Periodic Health Examination was the first such system, published in 1979, and the United States Preventive Services Task Force (USPSTF) followed suit thereafter.6,7 Several refinements based on an improved understanding of study methodology and relative risks and benefits have occurred since then, and the Grade of Recommendations, Assessment, Development and Evaluation (GRADE) scheme is now the most widely accepted hierarchical system. The GRADE scheme has defined quality of evidence as the confidence in the magnitude of effect for patient-important outcomes, with higher quality evidence conveying less uncertainty in the estimates of their results (Tables 23.1, 23.2).8,9 Well-designed and conducted RCTs represent the epitome of study design due to the minimal bias that results.8 Other study methodologies, although able to convey acceptable results, generally do not carry the authority of RCTs. Clinicians are accustomed to ascribing the RCT, in which interventions are compared between patient groups, as the most common and ideal form of trial methodology. Other types of trials, however, are often necessary before comparative studies of treatment can be conducted on human subjects. Phase 1 studies are safety studies in which toxicity profiles can be assessed, whereas phase 2 studies examine the efficacy of the treatment in question. Phase 3 studies are the typical clinical trial with which most clinicians are familiar, as they involve the study of an intervention compared with another treatment strategy or a placebo agent in two or more randomly allocated groups.10 Randomized controlled trials are considered to represent the highest level of evidence because they can minimize bias more than any other study methodology; however, such a distinction is achieved only by meeting certain criteria. Arguably the most important of these is appropriate randomization, in which the allocation of study subjects to treatment arms occurs completely by chance. This aims to achieve a balance between the known and, more importantly, unknown confounders of outcome.11 In theory, the only factor that consequently differs between study arms is the intervention under examination. No other type of study design achieves this objective. But for randomization to truly eliminate “treatment selection bias” (in which clinicians preferentially offer one treatment to certain types of patients), investigators and trial participants must not be able to predict what the results of randomization will be for the next patient. This is called concealment of allocation and it protects the integrity of the randomization process.12,13 Similarly, blinding of study participants and physicians is also crucial to minimizing bias in the assessment of study outcomes. Historically, the study subject is unaware of allocation in a single-blinded study, whereas the subject and investigator are unaware of allocation in double-blinded studies. For studies in which a subjective assessment of outcome is required, triple blinding also masks the outcome assessor from treatment allocation. Authors of RCTs are now strongly encouraged to explicitly identify which groups were masked and how, because the terminology of single-, double-, and triple-blind is open to interpretation.14 Finally, well-planned and appropriate statistical analyses, including the a priori determination of sample size, study power, and the use of an intention-to-treat analysis, are important in maintaining the internal validity of any RCT.8,15,16 Other threats to the validity of an RCT include, for example, a large loss to follow-up, a large proportion of subject crossover between groups, or unplanned and inappropriate early stoppage of a trial. Proponents of the GRADE system argue that, because of these issues, RCTs may not always represent the highest level of evidence and that well-conducted, large observational studies may provide better evidentiary quality in some settings.2 Table 23.1 Criteria for Assigning Grade of Evidence
Clinical Trials: Are They Authoritative or Flawed?
Clinical Trials Are Authoritative
The Hierarchy of Medical Evidence
Clinical Trials
Type of evidence: Randomized trial = high Observational study = low Any other evidence = very low Decrease grade if: Serious (–1) or very serious (–2) limitation to study quality Important inconsistency (–1) Some (–1) or major (–2) uncertainty about directness Imprecise or sparse data (–1) High probability of reporting bias (–1) Increase grade if: Strong evidence of association—significant relative risk of > 2 (< 0.5) based on consistent evidence from two or more observational studies, with no plausible confounders (+ 1) Very strong evidence of association—significant relative risk of > 5 (< 0.2) based on direct evidence with no major threats to validity (+ 2) Evidence of a dose–response gradient (+ 1) All plausible confounders would have reduced the effect (+ 1) |
Source: Atkins D, Best D, Briss PA, et al; GRADE Working Group. Grading quality of evidence and strength of recommendations. BMJ 2004;328: 1490. Reprinted by permission.
Table 23.2 Definitions of Grades of Evidence
High | Further research is unlikely to change our confidence in the estimate of effect. |
Moderate | Further research is likely to have an important impact on our confidence in the estimate of effect and may change the estimate. |
Low | Further research is very likely to have an important impact on our confidence in the estimate of effect and is likely to change the estimate. |
Very low | Any estimate of effect is very uncertain. |
Source: Atkins D, Best D, Briss PA, et al; GRADE Working Group. Grading quality of evidence and strength of recommendations. BMJ 2004;328: 1490. Reprinted by permission.
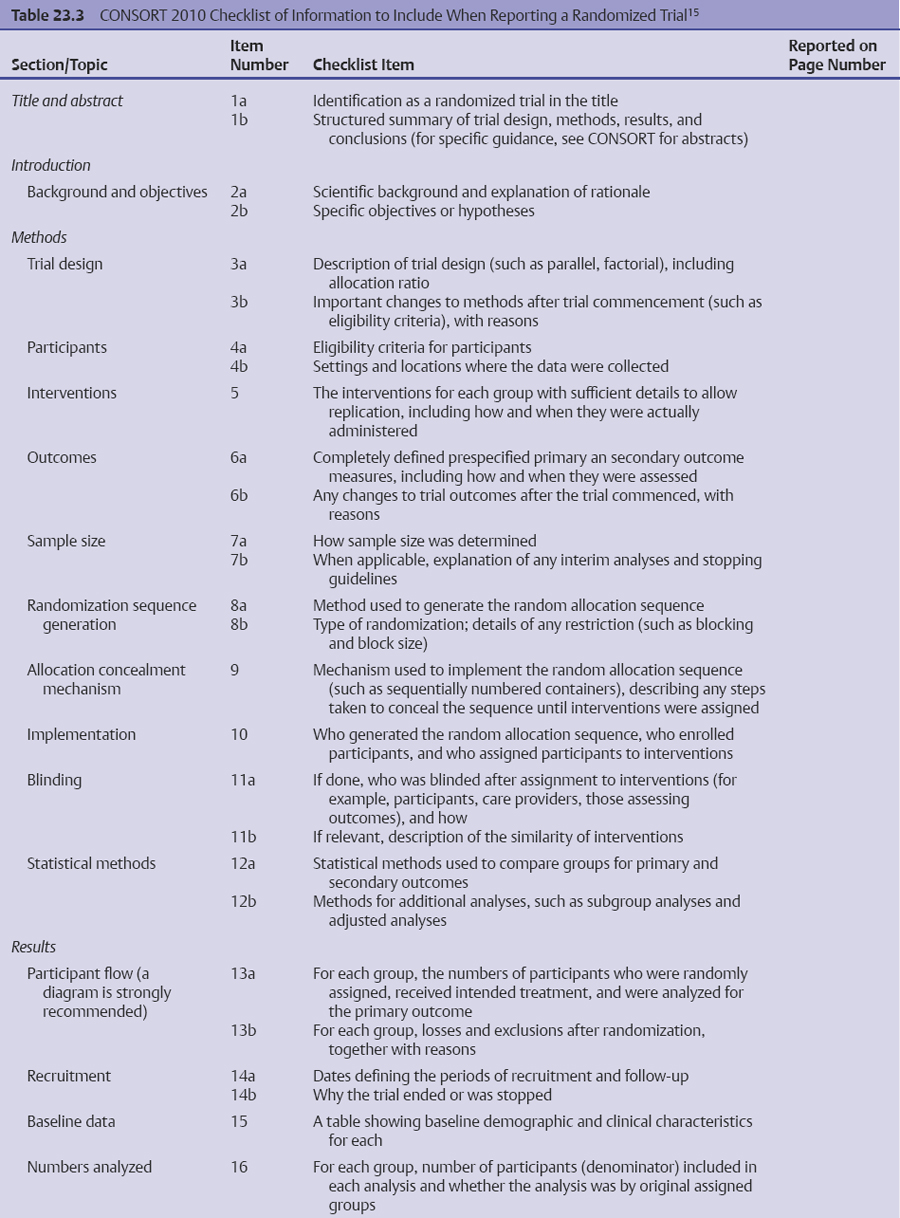
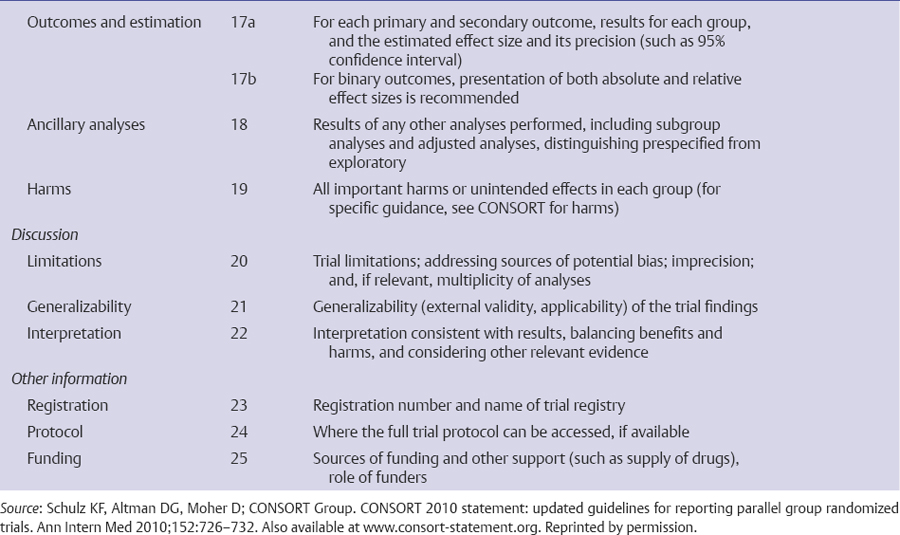
The only way for a clinician to critically evaluate the integrity of an RCT is by evaluating the final published work. Therefore, it is crucial that published RCTs contain enough information so that they can be appropriately judged. The Consolidated Standards of Reporting Trials (CONSORT) statement is a widely endorsed protocol of all essential elements that must be reported in published RCTs. The most recent version of CONSORT lists 25 mandatory elements, with an accompanying flow diagram to show the passage of participants through a trial (Table 23.3, Fig. 23.1).15,17,18 Many journals have officially adopted the CONSORT statement in their editorial assessment of trial reports, which has resulted in improvements in the quality of their trial reporting.19,20 A more recent study found that, despite improved reporting of trial characteristics after the publication of the CONSORT statement, the attrition of study subjects continues to undermine the quality of RCTs.21 It is clear that, although a well-designed and well-conducted RCT represents the most robust standard of medical evidence, each trial report must be subject to careful scrutiny.
Clinical Trials in Neurosurgery
The use of clinical trials for surgical research has lagged in comparison to medical research. Of the relatively few published RCTs in surgery, many suffer from methodological flaws that significantly compromise their validity.5 For some surgeons, obstacles to participating in or conducting randomized trials include issues of personal prestige, commercial interest, or an inherent belief in the superiority of surgical therapy. Additionally, the surgical community often rapidly disseminates and then accepts a new procedure as a therapeutic standard, thus eliminating the community equipoise that is necessary for randomization. Even if randomization is considered, technical learning curves associated with new operations and problems with blinding represent unique scenarios not encountered in medical trials.5 Also, patients are often reluctant to enter into surgical trials, particularly when the opposing arm is nonsurgical, due to the vast contrast between the treatment arms and the irreversibility of surgical treatment.22 Further obstacles include lack of funding or infrastructure and a lack of epidemiological expertise.
Despite these concerns, however, the use of RCT methodology in neurosurgery has seen a surge in recent years. In a recent systematic review of 159 neurosurgical RCTs, more than two thirds had been published since 1995.23 A 2004 systematic review of 108 neurosurgical RCTs, however, found that several design and reporting characteristics would benefit from improvement. These included the adequacy and reporting of sample size and power calculations, the appropriate concealment of allocation from involved investigators, and explicit reporting of randomization methods.24 The authors of the study encouraged increased adherence to the CONSORT statement as a means of improving standardization in neurosurgical RCT reporting. As of this writing, however, the major neurosurgery journals have not adopted CONSORT standards for reporting of RCTs. A systematic approach to trial design, such as one suggested by Kan and Kestle,25 might also reduce the methodological problems often observed in neurosurgical trials.
Despite the limitations and obstacles, RCTs have had a significant impact on neurosurgical practice. Prominent examples of this include the International Subarachnoid Trial (ISAT), the North American Symptomatic Carotid Endarterectomy Trial (NASCET), the EC-IC Bypass Study, the National Acute Spinal Cord Injury Studies (NASCIS I-III), the Corticosteroid Randomisation After Significant Head Injury (CRASH) trial, and the Surgical Trial in Intracerebral Hemorrhage (STICH).26–30 RCTs in allied fields, including the trial of temozolomide for patients with glioblastoma, have also contributed significantly to the treatment of neurosurgical patients.31 Clearly, neurosurgeons must familiarize themselves with the nuances of trial design and reporting.
Conclusion
Minimizing bias in clinical studies forms the cornerstone of the EBM movement. Well-designed and well-conducted RCTs represent the pinnacle of minimized bias because they balance all possible confounding factors and ensure masked outcome assessment and treatment allocation. Clinicians evaluating RCTs for use in practice, or for the development of evidence-based clinical practice guidelines, must continue to scrutinize individual studies to ensure that trials meet the methodological rigor required to render the highest quality of medical evidence. As the specialty of neurosurgery continues to embrace EBM, the need for neurosurgeons to become intimately familiar with RCTs and their applications will only continue to grow.
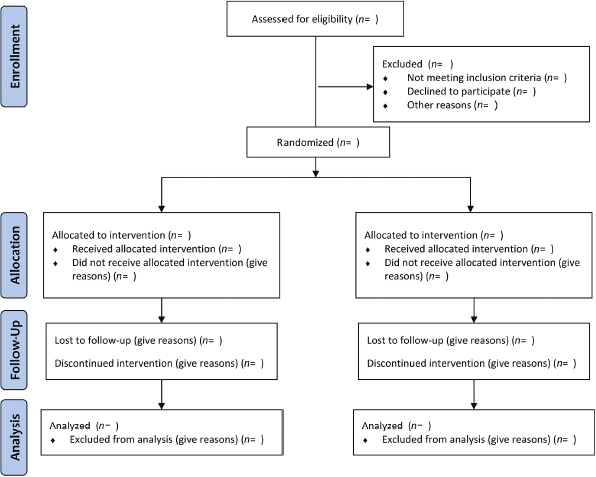
Fig. 23.1 CONSORT 2010 statement flow diagram. (From Schulz KF, Altman DG, Moher D; CONSORT Group. CONSORT 2010 statement: updated guidelines for reporting parallel group randomised trials. Ann Intern Med 2010;152:726–732. Also available at www.consort-statement.org. Reprinted by permission.)
The Flaws of Randomized Clinical Trials
Because it provides the best evidence of the efficacy of health care interventions due to its great potential to show cause–effect relationships, a well-designed and properly executed RCT is the best type of scientific evidence and is considered the paradigm for clinical research for evidence-based medicine.17,32,33
Compared with other scientific research designs, RCTs have the advantage of experimental characteristics, in which a factor to be studied is deliberately introduced to the subject of the research as a preventive or therapeutic intervention. As an attribute of experimental research, the investigator has better control over the events of the research than have investigators in observational studies. In addition, the factor being studied is introduced at the beginning of the study, and the participants are followed as long as necessary to determine the outcome.33
Despite being the best scientific research design available, RCTs with inadequate methodological approaches are susceptible to flaws that generally are associated with exaggerated treatment effects.32,34–36 Therefore, before accepting the results, readers should critically appraise the trial to exclude the most frequent causes of deviation from the truth. If the trial has eliminated flaws, there is a good chance that its results are reliable.37
Potential Flaws in Randomized Controlled Trials
A critical appraisal of RCTs should aim to find potential biases that can invalidate the reported results, but such an appraisal is possible only if the design, execution, and analysis of the trial is meticulously described in published articles.34,38
An important dimension of the quality of a clinical trial is the validity of the generated results,35 and a useful distinction between internal and external validity was proposed in the middle of the last century.39 Internal validity means that the differences observed between groups of patients allocated to different interventions may be attributed to the treatment under investigation instead of random error. External validity or generalizability is the extent to which the results of a clinical trial provide a correct basis for generalization to other circumstances. Therefore, internal validity is essential for external validity because there is no way to generalize invalid results.35,39
Internal validity can be affected by bias. Bias is the degree to which the result is skewed away from the truth, and it often reflects the human tendency to either consciously or subconsciously “help” things work out the way it seems they should go. For researchers, bias may happen to favor the results they want; for participants, a bias might be useful for their preconceptions of how the results will affect them, for example, getting better when they take the pill.37 Biases are generally found at critical points when the trial is developed, and to determine whether biases have been reduced or eliminated, each stage of the study, especially the methodology, should be reviewed using simple questions.33,37,38 In clinical trials, biases are classified into four categories: selection (occurring in the group allocation process), performance (observed when there is a difference in the provision of care apart from the treatment under evaluation), detection (also called observer, ascertainment, or assessment bias, which is verified in the assessment of outcomes), and attrition (due to handling of deviations from the protocol and loss of follow-up).35
Readers can do a critical assessment of the quality of an RCT by asking several fundamental questions regarding the methodology of the study33:
1. Were the characteristics of participants in both groups similar at the start of the study?
2. Was the allocation of participants randomized for both groups?
3. Were the participants concealed for the allocation of participants in both groups?
4. Were the researchers and participants blinded to treat- ment?
5. Were the results analyzed on an intent-to-treat basis?
6. Were participants lost to follow-up?
After the methodology has been analyzed and found adequate, the applicability of the results should be analyzed. With the intention of improving the quality of published clinical trials and facilitating critical appraisal and interpretation for readers, a group of scientists and editors of some leading medical journals developed the Consolidated Standards of Reporting Trials (CONSORT) statement,17 which was later revised.36,38,40
The quality of RCTs can be practically assessed by using the Jada scale, which ranges from 0 to 5 points.41 This tool aims to assess whether the study was described as randomized (including the use of words such as randomly, random, and randomization) and double-blind, and whether it includes a description of withdrawals or dropouts. A score of 1 point is given for each answer. An additional score of 1 point each is given if the method used to generate the sequence of randomization and the method of double-blinding were described and considered adequate. The method to generate randomization sequences was considered adequate if it allowed each study participant to have the same chance of receiving each intervention being assessed. Double-blinding was considered appropriate if it was stated or implied that neither the person doing the assessment nor the study participants could identify the intervention being assessed. The study is considered valid if it reaches a minimum final score of 3 points.
The main steps of RCTs that can be affected by biases are presented here with some classic examples.
Methods
Participants
Recruitment
How fairly were the participants recruited? Is the sample representative of the population?
Randomized controlled trials address an issue relevant to a particular population that has a characteristic condition of interest. A sample of participants is usually selected to restrict the source population by using eligibility criteria typically related to age, sex, clinical diagnosis, and comorbid conditions. The participants selected for study should appropriately represent the population of interest or source population. The ability to generalize the results of the RCT depends on its external validity, or how the population of the study represents the source population, the eligibility criteria, and the methods of recruitment. A trial that establishes many exclusion criteria selects a very specific population that compromises the application of its results to other contexts. To be representative, the study groups should have random recruitment and only relevant exclusion criteria.33,37,38
Potential participants sequentially or randomly recruited from the whole population of interest and the source of participants should be clearly described, for example, first presentation, emergency presentation due to subarachnoid hemorrhage, or participants with nonruptured aneurysms demonstrated on computed tomography or magnetic resonance imaging. The methods of recruitment, such as through referral or self-selection (for example, advertisements), are very important. Eligibility criteria do not affect the internal validity of the trial because they are applied before randomization. Nevertheless, they affect the external validity.33,37,38 Obtaining a sequential or random sample of the population of interest for RCTs is difficult because of the need for consent. As these studies generally will not be representative of the whole population with a specific problem, a clear idea of who they do represent is necessary and should be described in the study as the severity, duration, and risk level of the participant to ensure that the target population was defined.33
The protocol should include only exclusion criteria relevant for the study methods, for example, the exclusion of small children or people with sensorial aphasia from a study requiring answering verbal questions. It should not include irrelevant criteria, such as weight or height, for the question to be answered.
The description of settings and locations of the trial should be precise because they can affect the external validity. Health care institutions vary greatly in their organization, experience, and resources. The baseline risk for the medical condition under investigation, as well as climate and other physical factors, economics, geography, and the social and cultural background, can all affect a study’s external validity. If a trial aiming to assess the efficacy of treating cerebral aneurysms with clips or coils was done by experienced specialists in a referral neurovascular center, its results cannot be applied for participants treated by general neurosurgeons in a general hospital (performance bias). In a similar manner, when the study is a multicenter trial, the different centers should be well described because each one may have different levels of assistance or the assistant physicians may have different expertise, causing a performance bias. Several examples of possible performance biases appear in the ISAT, which compared the use of coils and clips for cerebral aneurysms.26 Differences in the selected centers included the level of expertise in endovascular treatment, and the different contributions of each center, which suggest that an appreciation of the indications of clipping versus coiling differed from one center to another. These flaws were pointed out in many subsequent publications.42–49 Therefore, a description of settings and locations should provide enough information to allow readers to judge whether the results of the trial are relevant to their own setting.38
Sample Size
The number of participants required for a significant study varies with the type of outcome studied, and for scientific and ethical reasons the sample size for a trial should be planned with a balance between clinical and statistical considerations.37,38 The ideal number of samples should be large enough to have a high probability (power) of detecting as statistically significant a clinically important difference of a given size if such a difference exists.38 The size of effect considered important is inversely related to the size of the sample needed to detect it. Therefore, large samples are necessary to detect small differences. Elements to be included in sample size calculations are (1) the estimated outcome for each group (the clinically important target difference between groups); (2) the β-error level; (3) the statistical power of the β-type error level; and (4) for continuous outcomes, the standard deviation of the measurements.37 How the sample size was determined should be clearly stated in the methods. If a formal method was used, the researchers should identify the primary outcome on which the calculation was based, all the quantities used in the calculation, and the resulting target sample size per comparison group.37
Frequently, studies with small samples arrive at the erroneous conclusion that the intervention groups are not different when too few participants were studied to make such a statement.50,51 Reviews of published trials have consistently found that a high proportion of trials have very low statistical power to detect clinically significant treatment effects because they used small sample sizes, with some probability of missing an important therapeutic improvement.52–54 When the study’s conclusion is that “there is no evidence that A causes B,” readers should first ask whether there is enough information to justify the absence of evidence or there is simply a lack of information.50 An example is a trial that compared octreotide and sclero-therapy in participants with variceal bleeding, in which the authors reported calculations suggesting that 1,800 participants were needed, but they arbitrarily used a sample with only 100 participants, accepting the chance of a type II error.54 If the stated clinically useful treatment difference truly existed, this trial had only a 5% chance of getting statistically significant results. As a consequence of this low power, the confidence interval for the treatment difference is too wide. Despite a 95% confidence interval including differences between the cure rates of the two treatments of up to 20 percentage points, the authors concluded that both treatments were equally effective.50 Another example can be observed in an overview of RCTs evaluating fibrinolytic (mostly streptokinase) treatment to prevent the recurrence of myocardial infarction.55 The overview showed a modest but clinically useful, highly significant, reduction in mortality of 22%, but only five of the 24 trials had shown a statistically significant effect with a p value of < 0.05. Because of a lack of significance of many individual trials, the recognition of the true value of streptokinase was long delayed.50
Methods for calculating the sample size for different types of scientific research have been reviewed.56 To quickly analyze the adequacy of the sample size of a specific trial, there are two rules of thumb to determine how many participants are needed.57 For studies with a binary outcome, approximately 50 “events” are necessary in the control group to have an 80% power of detecting a 50% relative risk reduction. For example, if the expected event rate is 10%, 500 participants are necessary for each group. For studies with a continuous outcome (such as height, weight, or blood pressure measurements), in which each patient contributes information, 50 patients per group might be sufficient. For events such as a heart attack or episodes of ischemic stroke, the number of participants required depends on how common the event of interest is.37
Randomization
Did the allocation of participants allow similarity between the groups? Were the study groups comparable?
Besides the variables being measured, different basic characteristics among participants (confounding factors) can affect the outcome of the study. To reduce or eliminate these factors, the groups being studied should match as closely as possible in every way except for the intervention (or exposure or other indication) at the beginning of the study, and ideally participants should be assigned to each group on the basis of chance (a random process) characterized by unpredictability. If the groups are different from the beginning, any difference in outcomes can be due to nonmatched characteristics (or confounding factors) rather than the considered intervention (or exposure or other indicator).12,33,37,38
Simple randomization ensures that similar numbers are generated in both trial groups, and practically comparable groups are created for known and unknown prognostic variables. Restricted randomization uses procedures to control randomization to achieve a balance between groups. Block randomization aims to ensure similar numbers of patients in each group, and stratified randomization allows the groups to be balanced for some prognostic patient characteristics.11,58,59
Sequence Generation
Many methods of sequence generation are adequate, but it is not possible to judge the adequacy of generation from terms such as random allocation, randomization, or even random.38 The methods used to generate the random allocation sequence, such as a random number or computerized random-number generation, should be explained so that the reader can better assess the possibility of bias in group allocation. Random allocation has a precise technical meaning, indicating that each participant of a clinical trial has a known probability of receiving each treatment before one is assigned, but the actual treatment is determined by a chance process and cannot be predicted.11,38
When nonrandom, “deterministic” allocation methods such as alternation, hospital number, or date of birth are used, the word random should not be used.38,58 Empirical evidence indicates that these trials have a selection bias,32,34,35 probably due to the inability to adequately conceal these allocation systems.38 Examples of possible selection biases in the ISAT included the established opinions of investigators as to which treatment would benefit patients with specific aneurysms; an endovascular approach was the favored treatment for basilar aneurysms because of the high surgical risks, whereas surgery was preferred for middle cerebral artery aneurysms. The same problem occurred with the size of aneurysms (92 to 93% were 10 mm or less in size and 50% were 5 mm or less), causing a bias that favored endovascular treatment.45,47,49
Allocation Concealment and Blinding
Were the participants, those administering the interventions, and those assessing the outcomes blinded to group allocation?
Methods to guarantee adequate comparison between groups vary according to the type of study. The experimental method (such as an RCT) is considered ideal because it allows the researcher to randomly allocate participants to groups, making these groups comparable.33,58 Therefore, ideally, participants should be assigned to each group on the basis of chance (randomly), which is characterized by unpredictability, and this can be done using random allocation sequences. In some circumstances, however, randomization is not possible for ethical reasons or because few participants are willing to be randomized.11,58 Unrandomized studies of concurrent groups treated differently on the basis of clinical judgment or patient preference, or both, will need careful analysis to take into account the differing characteristics of the participants and may still be of doubtful value. A failure to use randomization when it could be used may fatally compromise the credibility of the research.11
A generated allocation schedule must ideally guarantee allocation concealment to prevent investigators and participants from knowing the treatment before participants are assigned.33,37,38,60,61 However, the randomization process should be carefully conducted to prevent a selection bias that renders the groups incomparable.33,37
In controlled trials, blinding keeps study participants, health care providers, and sometimes those collecting and analyzing clinical data uninformed of the assigned intervention, so that they will not be influenced by that knowledge.38 Trials in which participants and assessors are blinded from groups the participants are allocated to are called double-blind studies, and trials in which either the participants or the outcome assessors are blinded to the group allocation are called single-blind.
Related posts:
 Management of Symptomatic Carotid Stenosis
Management of Symptomatic Carotid Stenosis
 Surgical Removal of Tuberculum Sellae Meningiomas: Endoscopic vs. Microscopic
Surgical Removal of Tuberculum Sellae Meningiomas: Endoscopic vs. Microscopic
 The Application of Artificial Discs
The Application of Artificial Discs
 Management of Trigeminal Schwannoma: Microsurgical Removal vs. Radiosurgery
Management of Trigeminal Schwannoma: Microsurgical Removal vs. Radiosurgery
 Treatment of an Arteriovenous Malformation in Eloquent Areas
Treatment of an Arteriovenous Malformation in Eloquent Areas
 Resection of Gliomas in Eloquent Areas of the Brain
Resection of Gliomas in Eloquent Areas of the Brain
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


